
Designing Traceable Product States for an AI Ingredient Educator
TL;DR:
I designed an ingredient question workflow grounded in structured records, with explicit supported, conflicting, undocumented, and unsupported states. Validation, warning, no-data, and stop states ensured unsupported claims could not appear as verified answers. The work was about disciplined state design under incomplete and conflicting data, making uncertainty visible instead of masking it as confidence.
What Broke:
Users were asking cosmetic questions in a domain where incomplete, conflicting, or unsupported data could easily produce misleading answers if the system was too eager to respond.
The product needed to make four things explicit:
What the system could support
What it could not support
Why an answer was limited or downgraded
When it should refuse rather than speculated
The main risk was a confident answer that blurred the boundary between verified evidence and false assumptions.
What I Designed:
The product could respond in one of four states:
Supported: the dataset contained sufficient evidence to answer
Warning: the dataset contained partial or conflicting evidence, so the answer had to be qualified
No data: the current dataset did not cover the question
Refusal: the question was outside the supported scope or under-evidenced in a way that made answering inaccurate
I also defined the rules that controlled transitions between those states.
Generate answers only after validation checks are passed
Handle conflict before answer generation
Link source evidence for every supported claim
Explicit refusal for unsupported question types
Visible no-data and undocumented states instead of fallback language
This shifted the product from “generate an answer if possible” to “only answer when the evidence boundary permits it.”
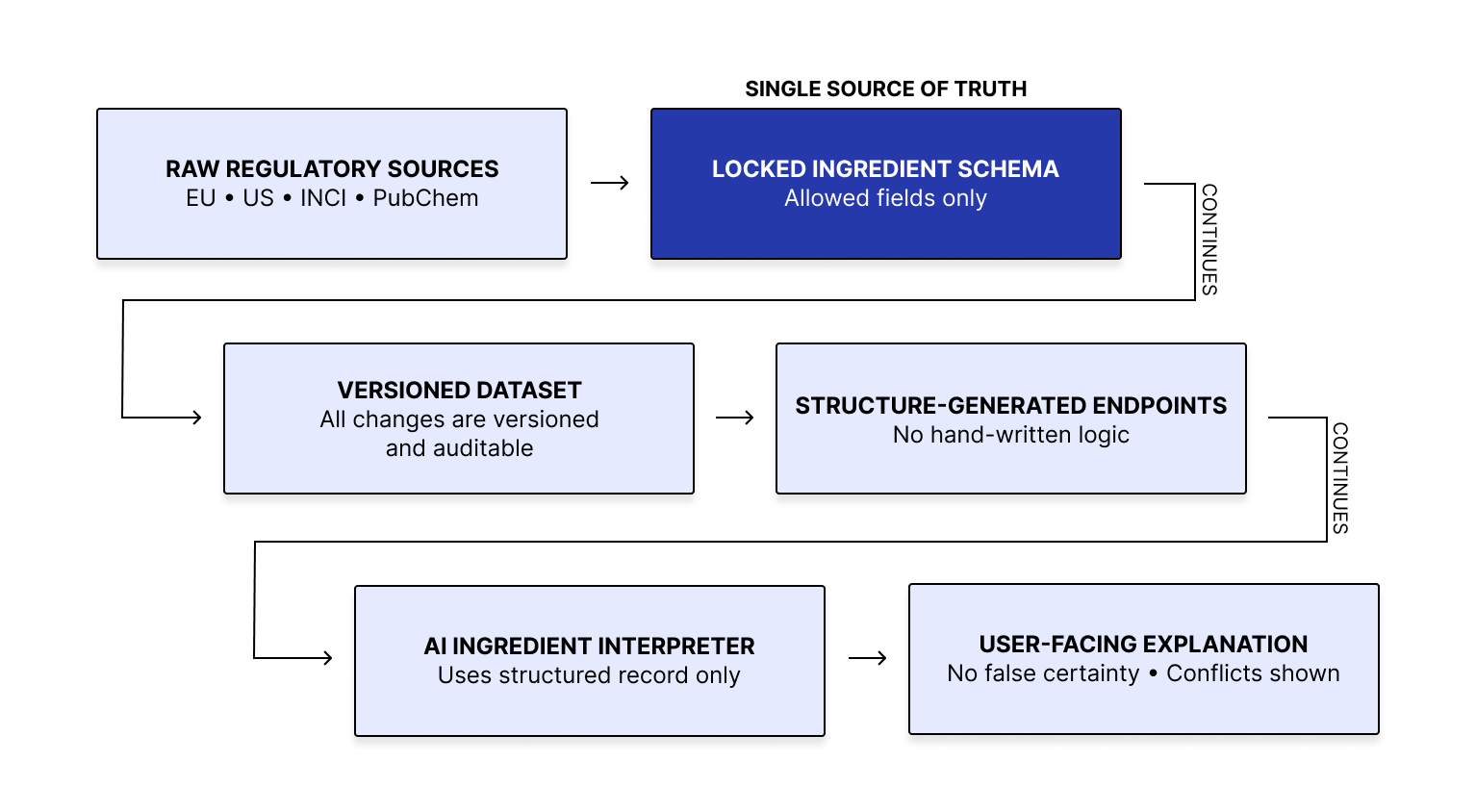
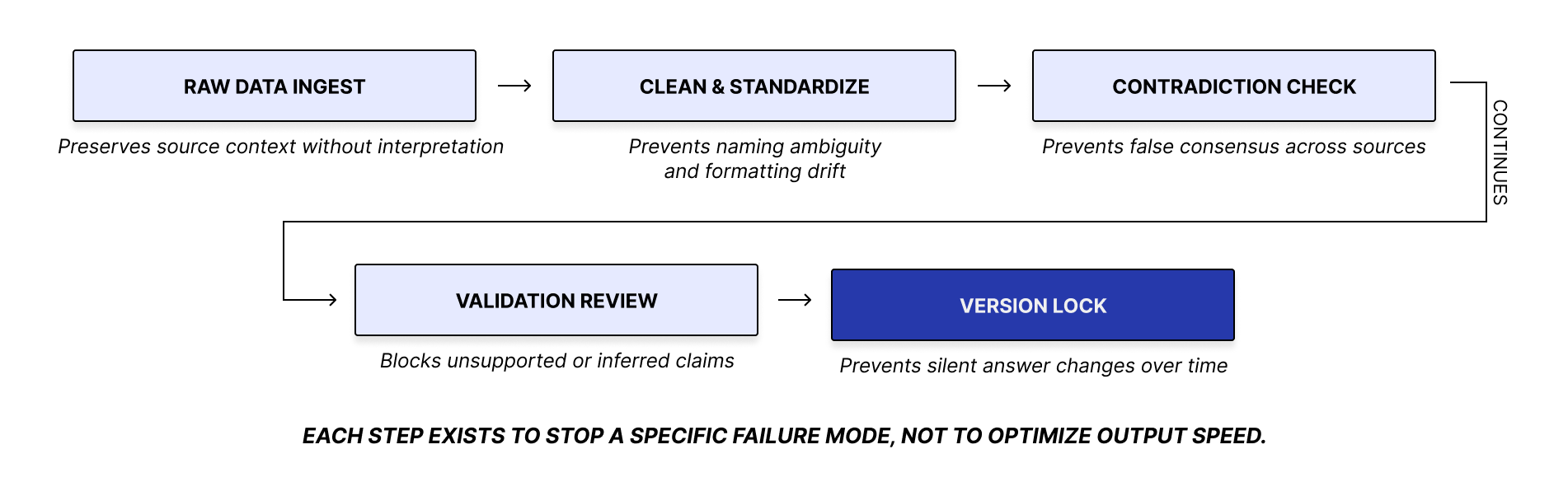
Decision Logic:
I defined a fixed sequence for handling ingredient questions: normalize the ingredient, check scope, validate coverage, detect gaps or conflicts, assign the answer state, and only then generate a response with supporting evidence. It kept answer behavior consistent and prevented under-evidenced output from appearing as verified guidance. This is visualized below.
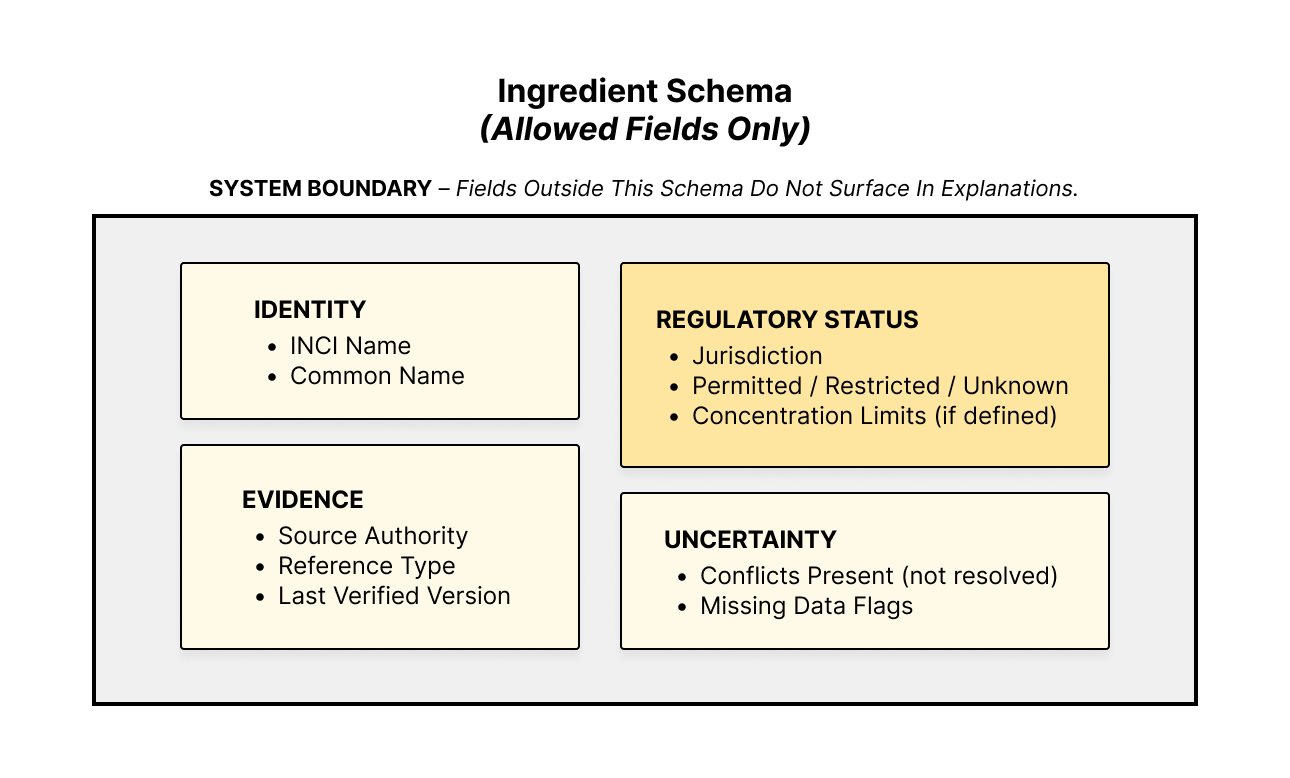
How Uncertainty Appeared in the Product:
A key part of the work was making uncertainty visible as a product state rather than hiding it. This mattered because each case required a different product response.
For example:
If records for an ingredient attribute conflicted, the system surfaced a warning instead of collapsing them into a single claim.
If the dataset had no validated record for the request, the system showed a no-data state.
If the user asked for medical, pregnancy, or formulation guidance outside product scope, the system refused rather than inferred.
Evaluation Results:
I tested the behavior against 50 realistic questions designed to pressure-test incomplete, ambiguous, and conflicting data conditions.
This test set focused on supported, warning-state, and no-data cases. Refusal behavior was defined separately for out-of-scope questions.
Across the 50 test queries, the system answered when evidence was sufficient, downgraded output when evidence was partial or conflicting, and surfaced no-data states when coverage was missing. The most trustworthy behavior came from staying inside the evidence boundary rather than extending beyond it.
What This Case Study Shows:
This case shows rigorous product-state design, explicit handling of no-data and contradiction, and discipline around traceability. The result was a narrower but more trustworthy product that made its limits explicit.