
Turning Regulate Data into an AI Ingredient Educator
TL;DR:
Philosophy: Designs AI systems that reduce uncertainty by constraining behavior with guardrails, enforcing data boundaries, and preserving traceability as systems scale.
Challenge: Ingredient data is fragmented across regulatory bodies and scientific sources, often conflicting, incomplete, or lack context. Most consumer tools smooth over these gaps, creating false certainty and eroding user trust
What I Did: The skincare AI educator aggregates cosmetic ingredient data and presents regulatory and dermatological science in a conversational, consumer-accessible format while preserving scientific accuracy through standardized data, strict system boundaries, and inference controls such as versioning, validation, and refusal logic.
Wins:
Zero hallucinations across 50 real-world test queries with 96% strict schema compliance
Deterministic, auditable responses tied to versioned regulatory data
Clear user-facing explanations that surface conflicts and unknowns instead of masking them
Project Info:
Role: Principal Designer, owning system design, data constraints, UX logic, and trust safeguards.
Scope: End-to-end design of a regulated AI information system, including schema definition, processing logic, validation strategy, refusal rules, and user-facing explanation patterns.
Platform: AI-powered ingredient education tool for regulated skincare data.
Tools: Figma, structured schemas, system modeling, validation testing, human-in-the-loop review, versioned data pipelines.
Overview:
The skincare ingredient educator is designed as a data pipeline, translating regulated cosmetic ingredient data into plain-language explanations without inference beyond verified sources. Controlled inputs, deterministic processing, and transparent outputs prevent the system from generating confident but unverifiable claims in a marketing heavy industry.
The Problem:
Ingredient information is fragmented across regulatory bodies that can disagree on naming, formatting, and recommended usage. Most consumer-facing tools resolve these inconsistencies by smoothing over gaps or substituting marketing language or pseudoscience for underlying data.
When information is unknown, a consumer tool should acknowledge that uncertainty. When sources conflict, the system should surface the conflict rather than conceal it. The core challenge is to design an ingredient interpreter is bound by scientific evidence and refuses to generate information beyond what can be verified.
Research & Insight:
To understand the landscape, I gathered cosmetic ingredient data from reliable scientific and regulatory sources and standardized it into a unified structure. This process surfaced how inconsistent the raw information was across sources and required substantial backend logic and protocol design to maintain coherence. In practice, the same ingredient could appear as permitted, restricted, or entirely undocumented depending on the source. Without structural guardrails, a consumer-facing tool would resolve these conflicts by presenting false certainty.
System Design:
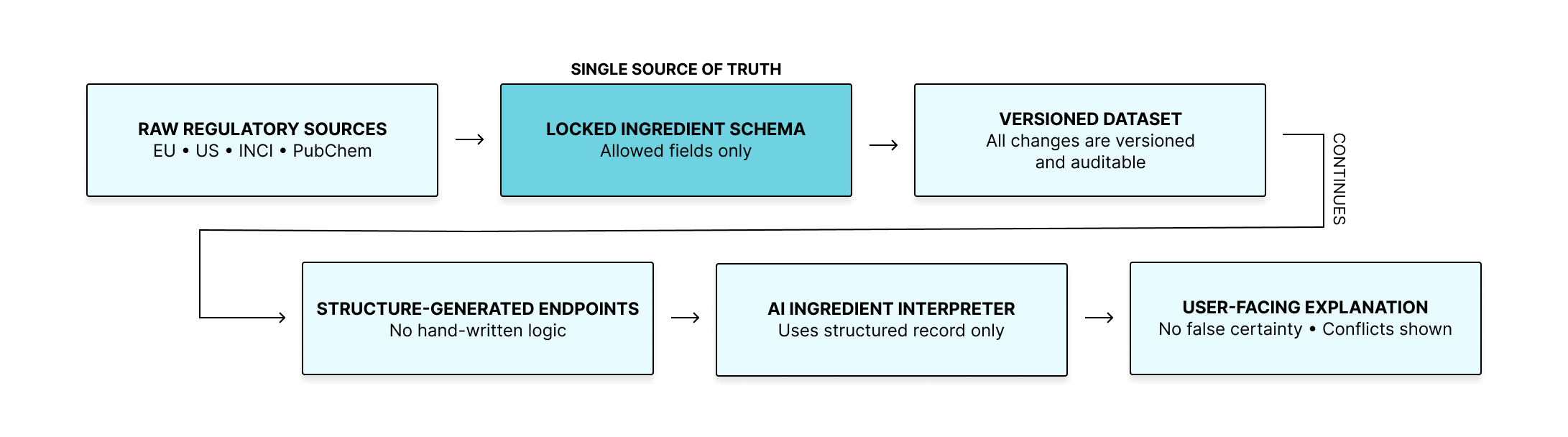
I created a single schema that defines every ingredient field the system is allowed to use. This schema acts as the source of truth for the entire platform. When it updates, everything else updates with it: the database, the endpoints, and the interpretation format.
This prevents drift, reduces ambiguity, and keeps the system aligned over time. Pipeline pictured below.
Consistent Processing:
Each ingredient moves through the same pipeline. If anything changes, the version changes. This makes every explanation traceable. Without a locked, versioned pipeline, explanations would silently change over time, making it impossible to audit prior answers or defend their accuracy.
Structure-Generated Endpoints:
The platform’s endpoints are generated from the schema. This ensures that what the system stores, serves, and presents is always synchronized.
The interpreter uses the structured ingredient record as its sole reference. If information conflicts, the explanation shows the conflict so the user can understand the boundaries of what’s documented. The tone remains steady and factual, without alarms or false certainty.

Testing:
I ran 50 ingredient-related queries designed to pressure-test the system under incomplete and conflicting data. The questions covered safety, compatibility, concentration limits, edge cases, and the messy, ambiguous queries real users ask. The goal was not to maximize coverage, but to surface failure modes such as hallucination, contradiction masking, and unsafe inference when data is missing or in conflict.
Results:
50 real-world queries
Zero hallucinations
96% strict schema compliance
All outputs schema-bound and version-traceable
Outcomes:
Most skincare tools rely on loose databases, optimistic phrasing, and pseudoscience. They can’t explain how they reached an answer. My final system behaves more like a regulated information service than a beauty tool. Every response ties back to a versioned dataset and a defined structure.
Stable, verifiable ingredient information
Consistent explanations tied to real data
Clear boundaries between what is known and not known
Full traceability through versioning
Next Steps:
Automate regulated data gathering
Expand coverage to 80+ ingredients
Test with non-expert users
Refine explanation depth and tone
The goal is to keep the interpreter both rigorous and approachable as it expands. As the system scales, the primary risk shifts from missing data to schema drift and uneven regulatory freshness, which will require automated provenance and update checks
Reflection:
This project is an example of how I design high-trust systems: start with structure, not gloss. Give the AI guardrails rooted in data, not vibes. Build something that stays honest even when the answers aren’t flattering or simple.
Good UX in regulated spaces isn’t loud. It’s steady. It’s traceable. It respects the user enough to tell the truth.