
Designing Guardrails for AI
TL;DR:
Designed an AI ingredient Q&A workflow that only answers when evidence clears validation.
Defined four explicit output states (Supported, Warning, No Data, Refusal) so uncertainty is visible and traceable.
Tested 50 realistic queries: 48/50 correct outcomes, with no confident answers generated outside the evidence boundary
Problem:
Cosmetic ingredient questions often involve incomplete, conflicting, or out-of-scope data. If the system answered by default, it could generate misleading, confident output. The product needed an evidence boundary: answer only when supported, qualify uncertainty when needed, show No Data when coverage is missing, and refuse unsafe or out-of-scope requests.
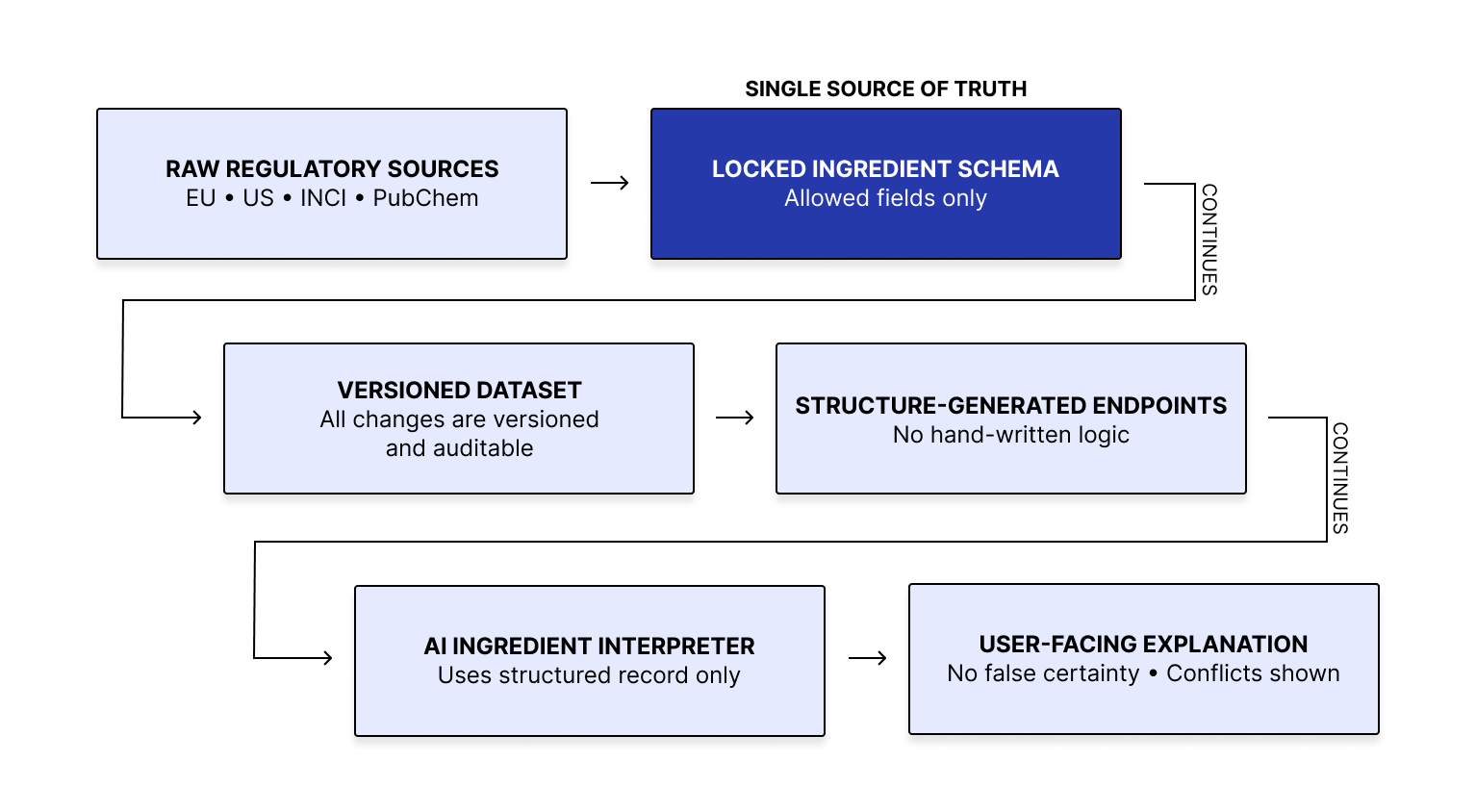
The diagram below was AI created and based on a review of the GitHub repository, Kanban tickets, and product documentation. It reflects the current product model, implemented backend foundation, and target product layers.
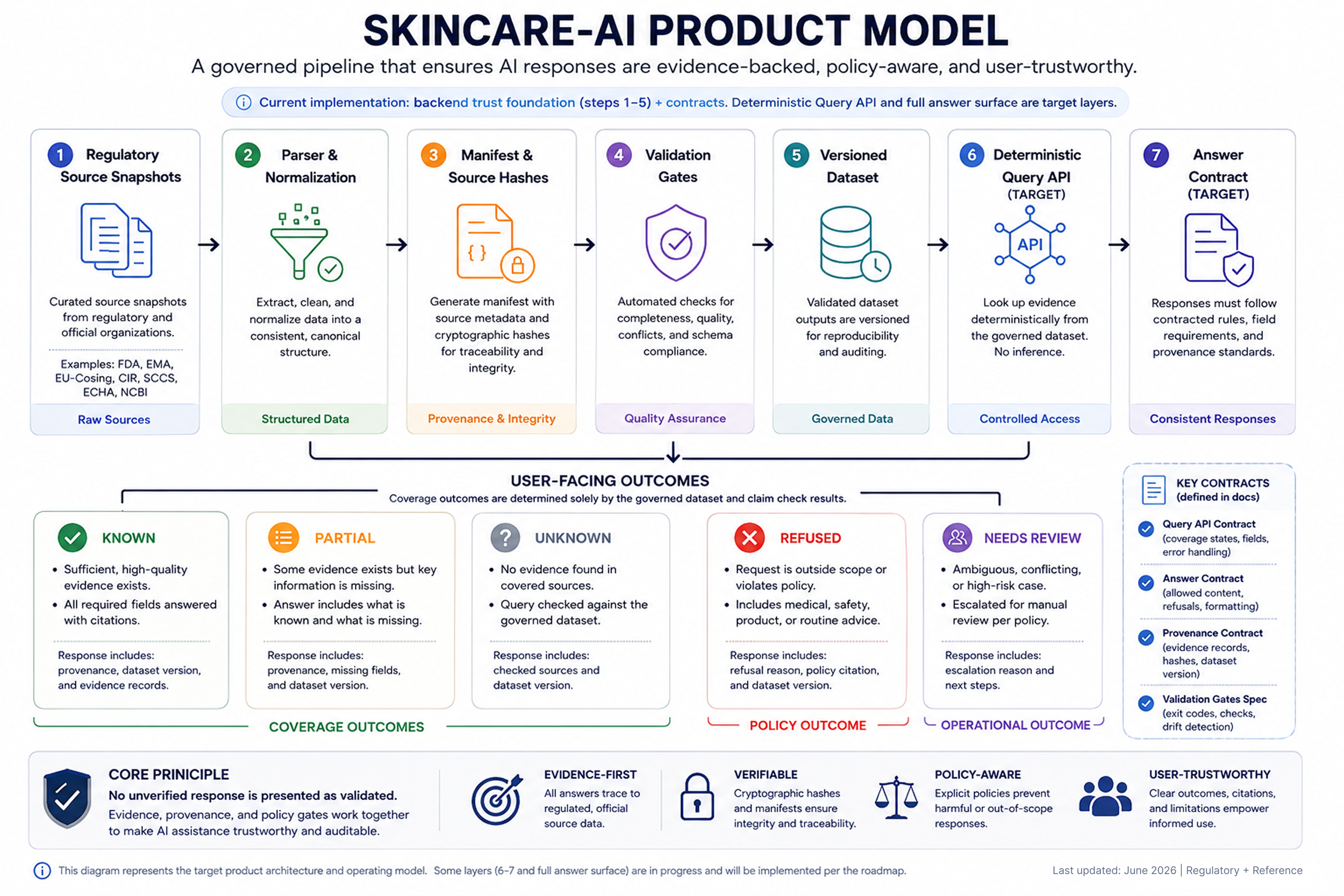
System Behavior:
The workflow assigns an explicit output state before any response is generated, so the UI can show limits, conflicts, and no-data conditions without guesswork
Output states
Supported: sufficient validated evidence
Warning: partial or conflicting evidence (qualified answer)
No Data: no validated coverage
Refusal: out of scope or under-evidenced for safe answering
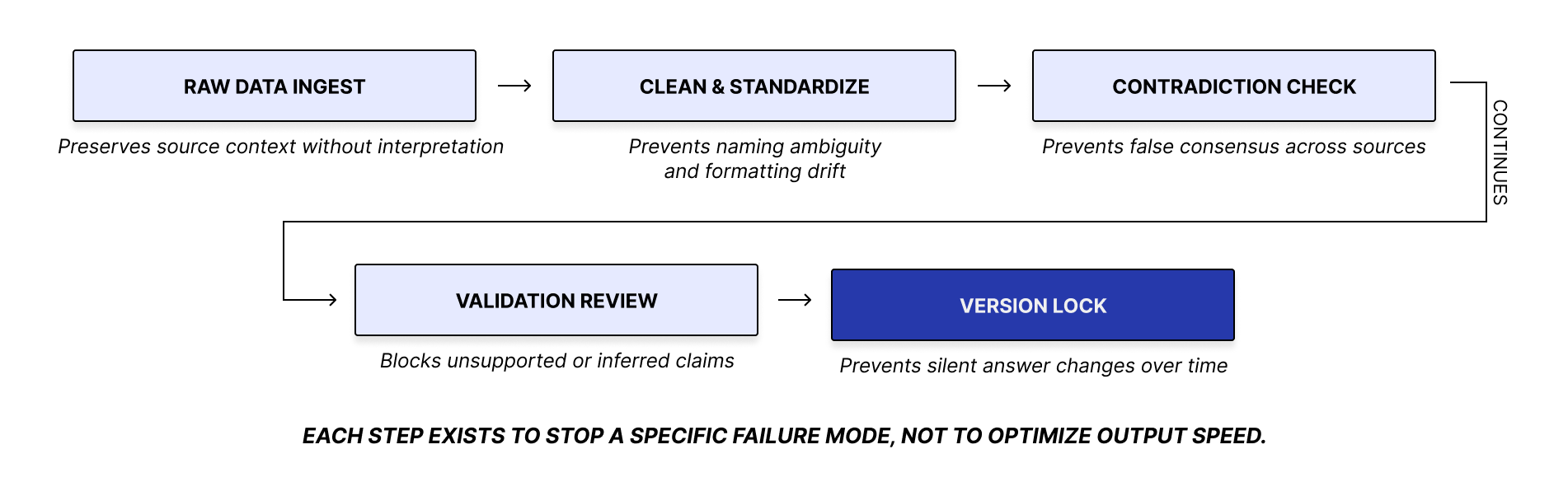
Gating rules (what prevents bad answers)
Validate coverage before generation
Resolve conflict before output
Require source evidence per claim
Refuse out-of-scope categories (medical, pregnancy, formulation guidance)
Show No Data instead of “helpful” filler language
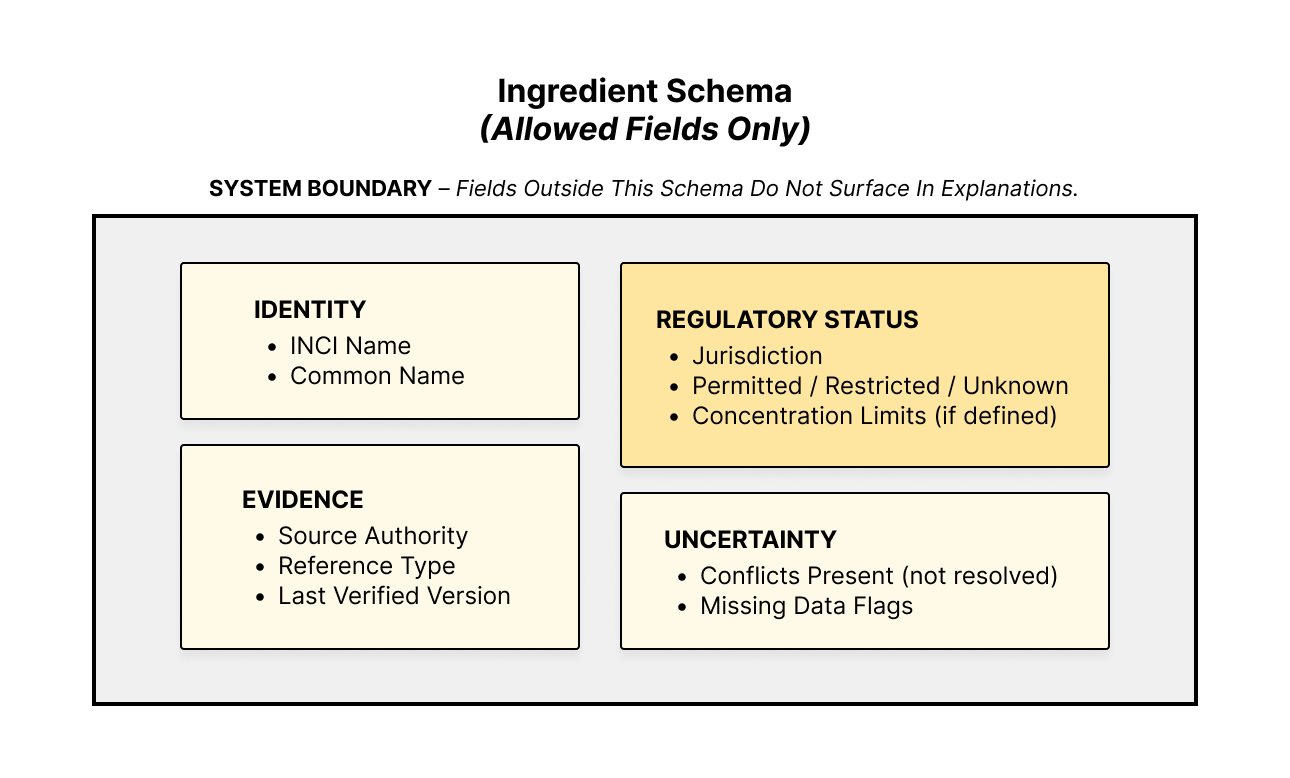
Decision Logic:
Normalize ingredient
Scope check (allowed question types)
Coverage validation (do we have records)
Conflict detection (contradictions, gaps)
Assign state (Supported, Warning, No Data, Refusal)
Generate response only if state allows, with linked evidence
How Uncertainty Appeared in the Product:
Conflicting records trigger Warning with surfaced disagreement, not a merged claim.
Missing validated records trigger No Data, not guessy fallback language.
Out-of-scope requests (medical, pregnancy, formulation) trigger Refusal, not inference.
Evaluation Results:
Pressure-tested with 50 realistic questions designed to hit incomplete, ambiguous, and conflicting conditions.
Outcome: 48/50 correct, with answers downgraded when evidence was partial and No Data shown when coverage was missing.
Correctness was scored by whether the system chose the correct state and whether supported claims were backed by linked record evidence.
My Role:
Designed the interaction model and product states for ingredient Q&A. Defined validation, no-data, conflict, and refusal requirements for consistent behavior. I specified evidence-linking rules so each supported claim is traceable to a record, and built the 50-query failure-mode test set and evaluated outcomes against state criteria
What This Case Study Shows:
Disciplined state design under uncertainty, explicit no-data and contradiction handling, and traceability-first decision support patterns used in security and regulated UX: explicit states, evidence boundaries, refusal behavior, and recovery paths under uncertainty.